
Abstract
The article discusses two versions of a smart data mining search engine for Saas DT (dtwin.city). The first version uses TF-IDF rankings to find relevant results based on user queries, but it has limitations in understanding context and unavailable data. The second version utilizes tokenization and embeddings to create a three-dimensional matrix for better search accuracy. This version solves all the mentioned problems and can handle erroneous or indirect queries. The article concludes by suggesting future developments for the project.
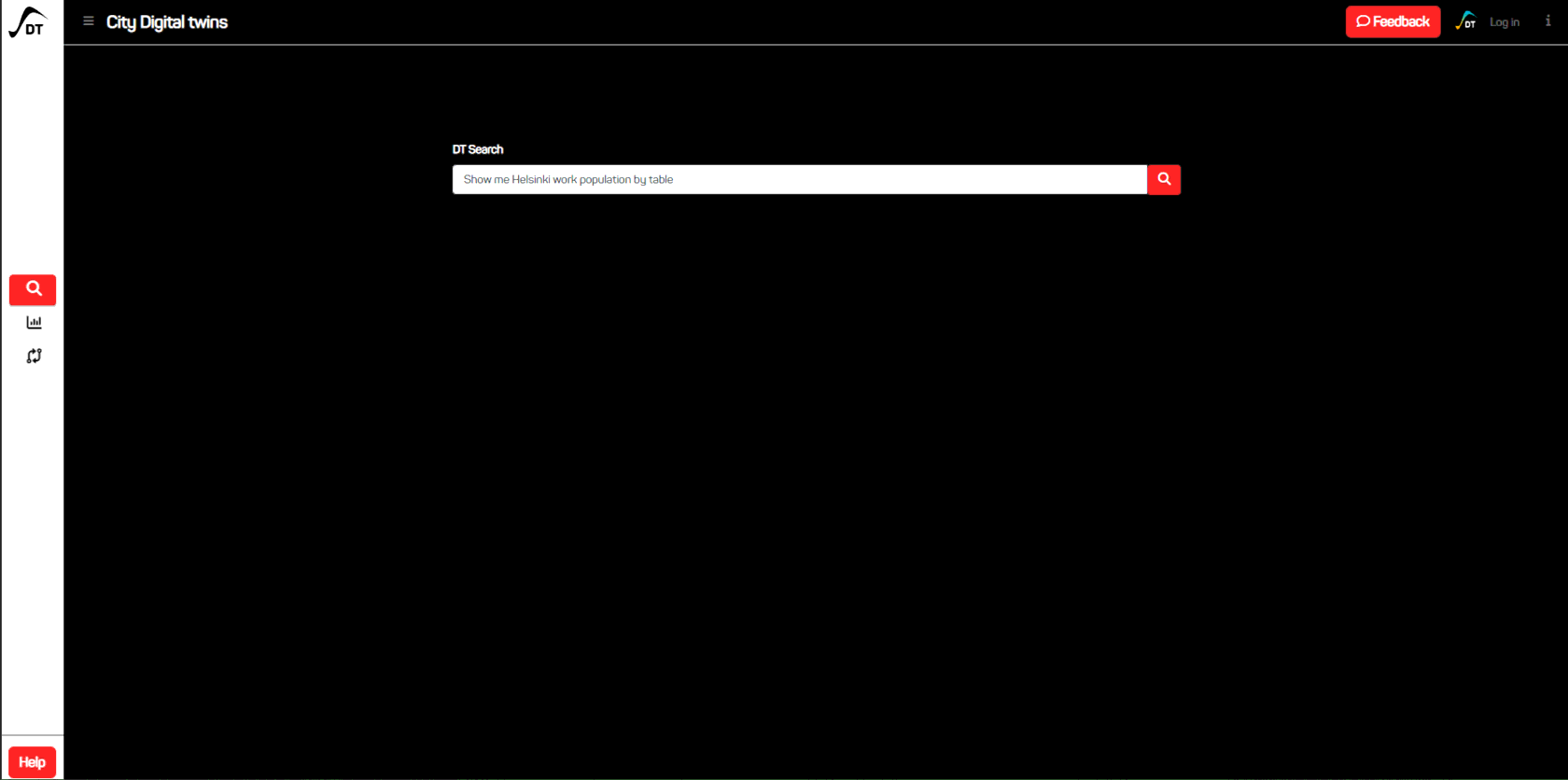
What the search is for:
Allows you to quickly retrieve the required location data in a specific form.
Expectation of the user from the search engine on our service:
When entering a location or/and indicator (and view type - Optional), it produces relevant results.
Problems for the system:
1) Location can be written as "capital of something", "output multiple cities", etc.
2) Indicator as something generic: "population", "cash", "income", etc.
3) Spelling errors are also possible.
4) The requested data is not available in the database.
Solution:
Version №1.
Working principle:
1) The incoming query is split into separate words, auxiliary parts of speech are removed. And are brought to the standard word form.
2) Service parts of speech and "rubbish" words are removed from the directory. And each line is split into separate words.
3) Each word from the query is compared with each word from the catalog up to 3 word errors.
4) The TF-IDF ranks the strings and finds the most relevant answers by cutting off 99% of the sample.
Result: Solves problems (2) and (3). But can't solve problem (1) because the search engine doesn't understand the context, and problem (4).
Version №2.
A special catalog is prepared (indexed by location + indicator, For example: Helsinki; Working age population):
1) An off-the-shelf solution from OpenAI is taken. Their dictionary and embeddings.
2) The indexed part (location + indicator) is tokenised (turned into a numeric vector (array)) using the dictionary. An example: "Helsinki; Work age population" -> "Hel sin ki ; Wo rk ag e pop ula tion" -> 74, 46, 528, 13, 7897, 811, 39, 10, 1641, 152, 913.
3) Each token corresponds to its embedding (vector of token characteristics).
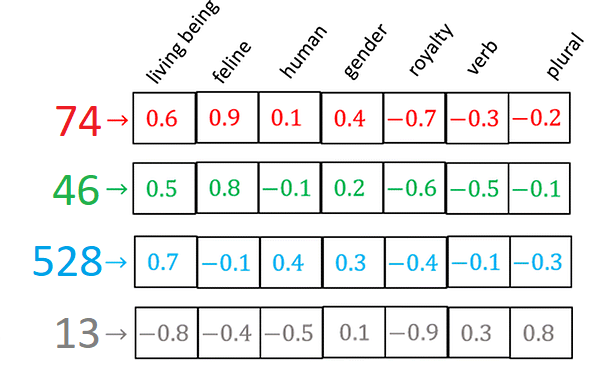
4) The whole directory is indexed in this way, resulting in a three-dimensional matrix.
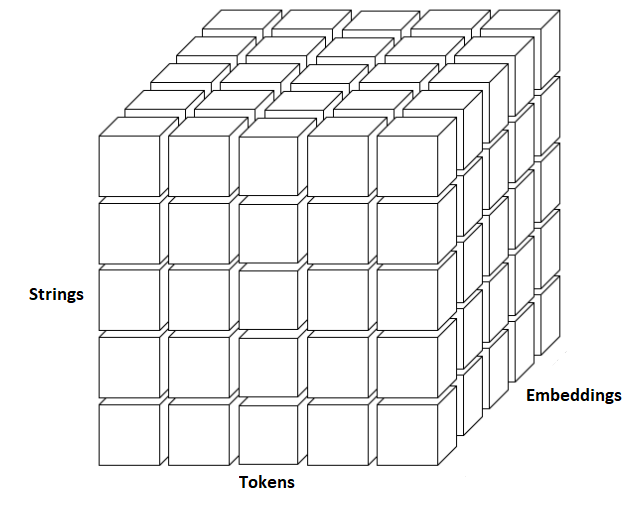
It is worth explaining. Embeddings have the advantage of being able to make "sense" (gross simplification). For example, if you put together trained embeddings: king + woman = queen, cat + child = kitten, etc.
Search:
1) The user query is tokenised and the embeddings are added.
2) Since embeddings are a vector, their cosine distance is found, between the query matrix and the matrix of each row of the directory.
3) The most relevant rows are found. It is ranked from minimum distance to maximum distance and 90% are cut off.
Result: Solves all the above problems.
Examples:
Search:
1) The user query is tokenised and the embeddings are added.
2) Since embeddings are a vector, their cosine distance is found, between the query matrix and the matrix of each row of the directory.
3) The most relevant rows are found. It is ranked from minimum distance to maximum distance and 90% are cut off.
Result: Solves all the above problems.
Examples:

Location and indicator entered with an error, but the search engine handled it
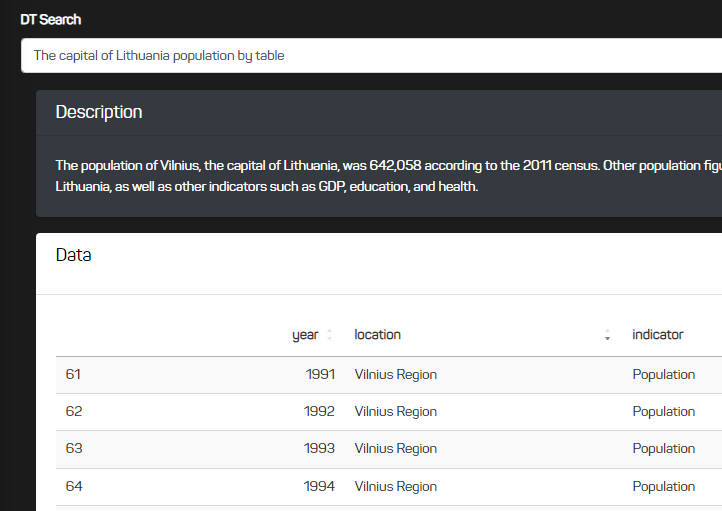
The "capital of Lithuania" is entered and one of the outputs is Vilnius

There is no GDP for Helsinki in the database, so the search engine outputs GDP for Finland
There is also a "Description" block that gives a small description on the internal data.
Conclusion
The search engine is able to find data even on erroneous or indirect (capital of something) queries, "understand" the context. And the user can get everything he asked for.
There are possible ways to develop the project. For example:
1) to give the user not several options, but to understand from the query what he needs exactly and offer the most relevant information;
2) to expand indexing (to include years, scenarios, etc.).
This is just the beginning!